别隻盯着最強模型了,Agent 場景更該看這類 Flash 檔模型
/朝聞通/最近,GLM 5.2 接連刷屏,國産模型又熱鬧起來了。
加上 DeepSeek V4、MiniMax M3.還有階躍星辰的 Step-3.7-Flash,國産大模型這一波可以說是你追我趕,熱度一下子又上來了。
可能有小夥伴對階躍模型不熟悉哈,階躍也是AI六小虎之一。

對于我們這些AI博主來說,日常就會使用到這些模型。針對這幾個模型的使用大體分為兩類。
「Pro/旗艦」和「Flash/效率型」兩類
Pro/旗艦:能力上限更高
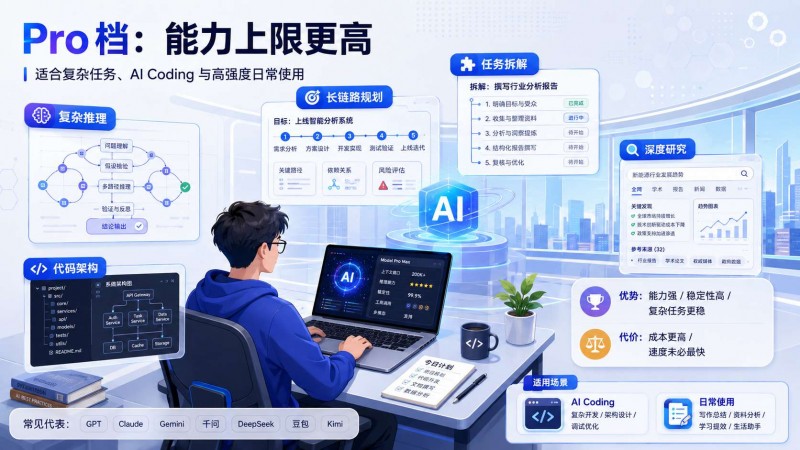
這一檔代表的是各家最強模型,通常适合複雜推理、長鍊路規劃、多輪任務拆解、代碼架構設計、深度研究這類場景。
Pro 檔可以理解為各家模型裡的旗艦能力層,主要面向複雜推理、代碼工程、長鍊 Agent 和高價值任務。海外代表包括 GPT 旗艦系列、Claude Opus、Gemini Pro;國内則可以對應 DeepSeek Pro 系列、千問 Max、高能力版 Kimi、豆包旗艦模型,以及 GLM 的高能力版本。
這類模型的優勢是能力強、穩定性高、理解複雜任務更穩。但代價也明顯:成本更高、速度未必最快。
Flash/效率型:模型能力的平衡點
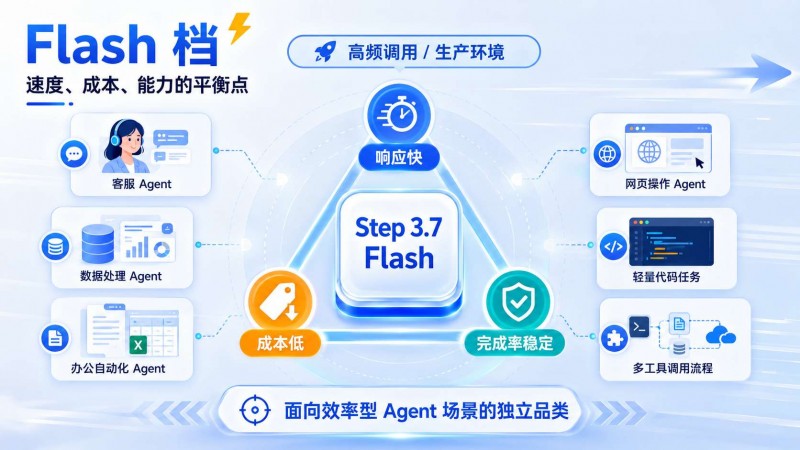
Flash 檔更适合生産環境裡的高頻調用。
它不一定追求所有榜單第一,但要做到三件事:響應快、成本低、任務完成率穩定。
在各種Agent調用,比如數據處理Agent,辦公Agent等等。需要連續性,成本控制的模型。
它不是“低配版 Pro”,準确說是面向效率型 Agent 場景的獨立品類。
測試一下實際效果怎麼樣。
工具選用Trae。全局使用統一的Trae設置,同一個項目。
每個模型都單獨跑一遍,測試開始前,項目環境和緩存狀态保持一緻。
制作項目測試集,查看模型在高頻任務,代碼質量,速度這些方面的能力。
Step-3.7-Flash
更适合放進 Agent 工作流裡。
之前做了一個新聞收集項目,需要開發一些測試類來對接口進行測試穩定性。
先讓AI整理一下測試提示詞。

把準備好的提示詞先丢給他。
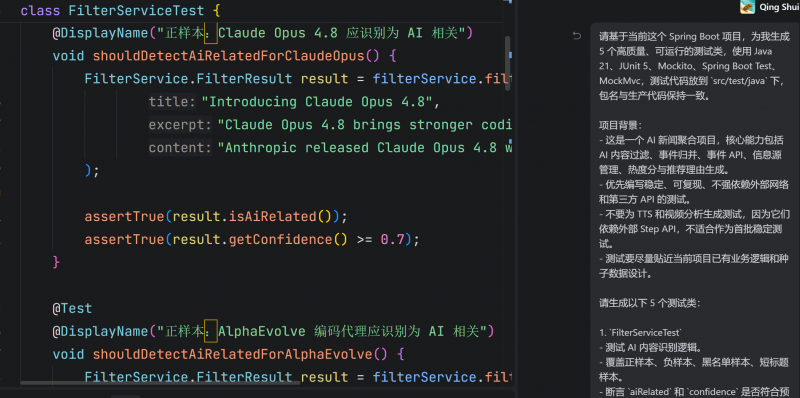
差不多5分鐘的時間,測試類就生成好了。

優化一下依賴,Agent自動進行了42次測試。
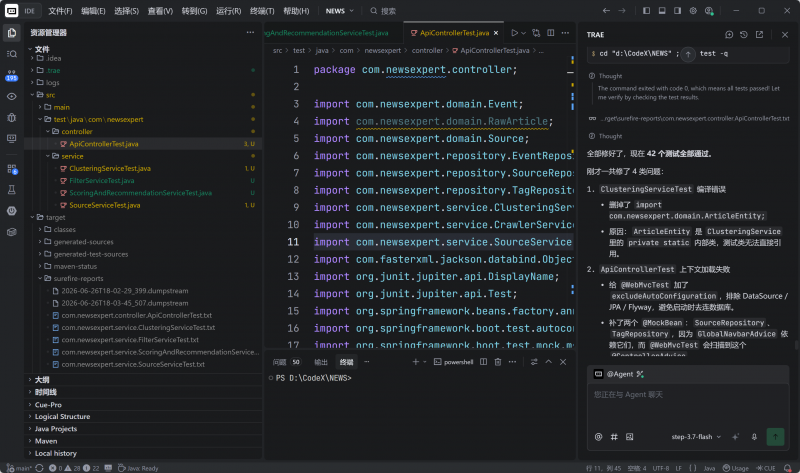
差不多一次性完成了80%,因為有些依賴問題,進行了二次檢測和修改。
代碼量在900行左右。
消耗token輸入和輸出合計在500萬左右。

消耗金額在3.5元左右。
然後我們用GPT5.4模型來進行同樣的測試。
GPT5.4
GPT5.4屬于Pro檔模型。
同樣的任務,GPT寫的代碼質量相對要好一點,中間沒有二次優化,對于代碼測試集來說,兩者差距并不大。
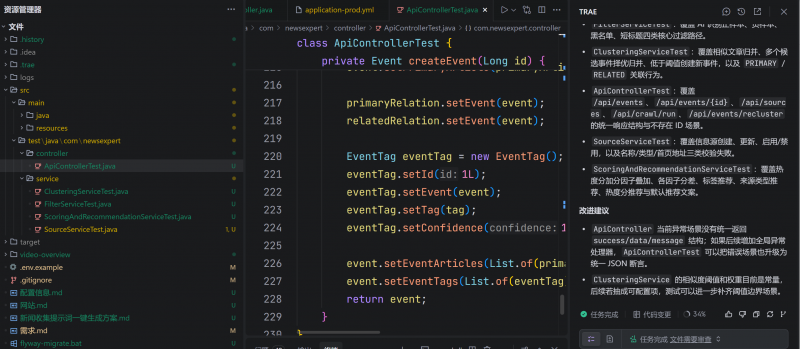
這種測試類型的代碼相對比較簡單,主要就是看模型的多路書寫能力。
GPT5.4的消耗就要比Step-3.7-Flash高出不少。因為GPT5.4需要長思考,所以對于簡單高頻的任務來說,時間上可能會比較慢。
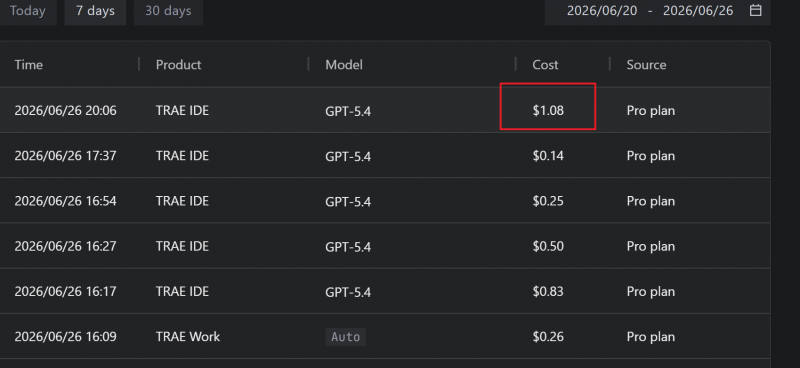
在Trae的資源管理裡面,可以看見這次消耗了1美元,那差不多就是Step-3.7-Flash的兩倍用量。國外的模型本來就比較貴,中國模型有天然的優勢。
效果差不多是GPT5.4的90%,成本為GPT5.4的1/2.
Deepseek-V4-Flash。
Deepseek 就不用多介紹了,屬于很多人接觸國産大模型的第一站。
它最大的特點不是花裡胡哨,而是穩定、便宜、生态成熟。你平時寫文章、改文案、做資料整理、寫代碼、做方案,大部分場景它都能頂上。
如果說其他模型有些是偏專項能力,Deepseek 更像一個通用底座。
這裡采用deepseek-V4-Flash。
同樣在Trae裡面測試這個模型生成測試集代碼的質量和實效。
幾分鐘後文件就創建好了。
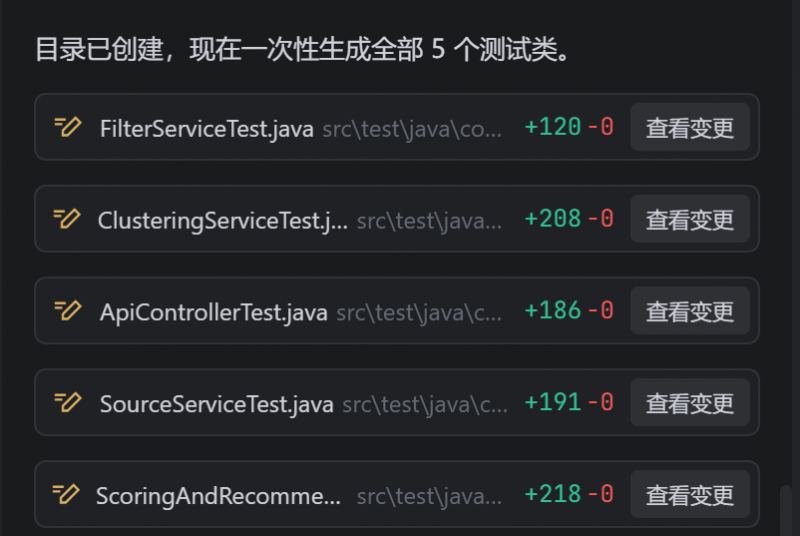
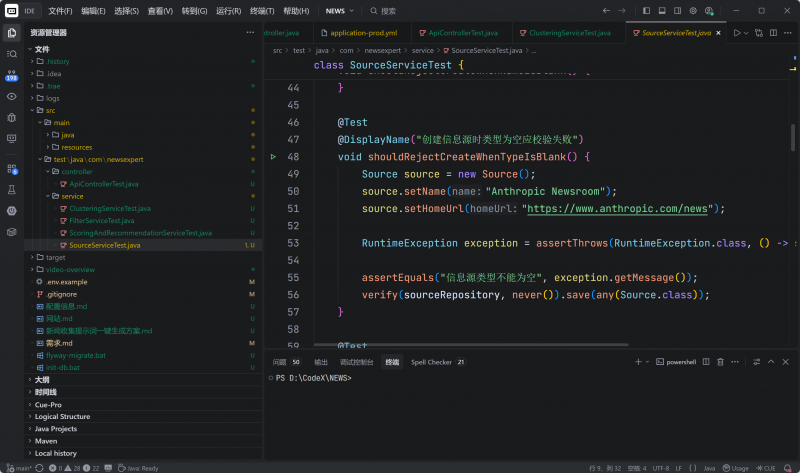
有一個小問題,代碼也有一部分報錯信息,需要二次調整。
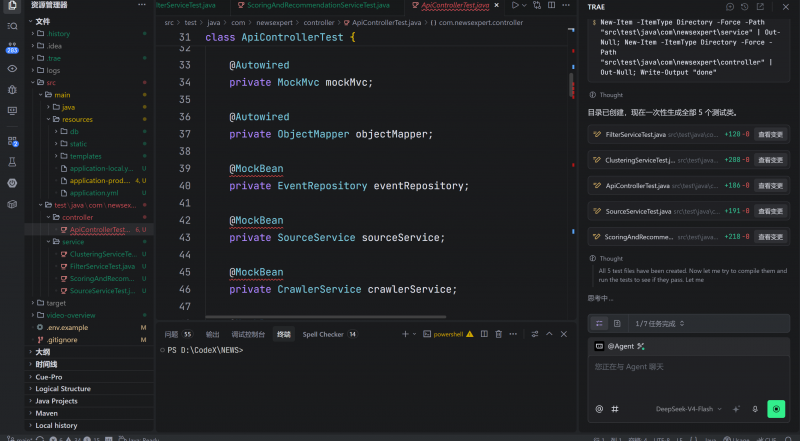
生成的代碼質量還可以,測試鍊路也可以跑通,隻不過有一個小問題,就是deepseek-V4-Flash自己寫的代碼進行測試的時候,消耗時間要比前面這兩個模型長一些,可能是測試内容比較多。
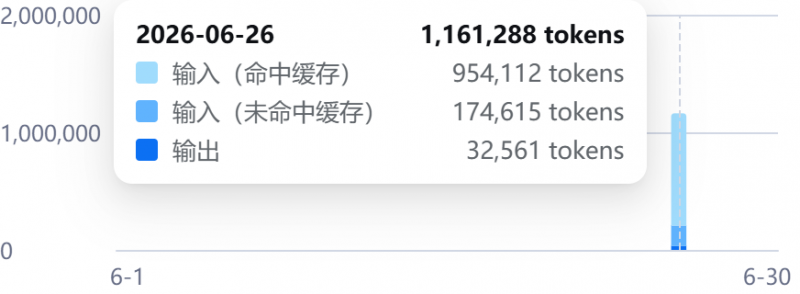
消耗了120萬左右的token,費用在0.2元左右,沒辦法,deepseek價格的确是他最大的優勢。
GLM5.2
GLM5.2屬于Pro檔模型。
GLM5.2 更适合放在長任務和 AI Coding 場景裡看。
這類模型不能隻看它會不會聊天。更關鍵的是,它能不能在一個比較長的任務裡堅持跑下去。
比如讓它讀完整項目代碼,理解目錄結構,分析問題在哪裡,然後一步步修改、測試、繼續修。這個過程對模型要求很高。上下文不夠,前面看過的東西後面就忘了;工具調用不穩,跑一半就斷;規劃能力不行,很容易改着改着跑偏。
GLM5.2 的定位就很明顯:長上下文、長任務、Agent 工作流。
同樣的任務進行測試看看效果如何。總體運行時間在15分鐘左右,這就是Pro模型的特點,能力強沒的說,但在實效上肯定就要落後一點。
需要的測試代碼也是正常生成的。
Agent自動幫我們進行了測試。對每個類别進行了多次測試。
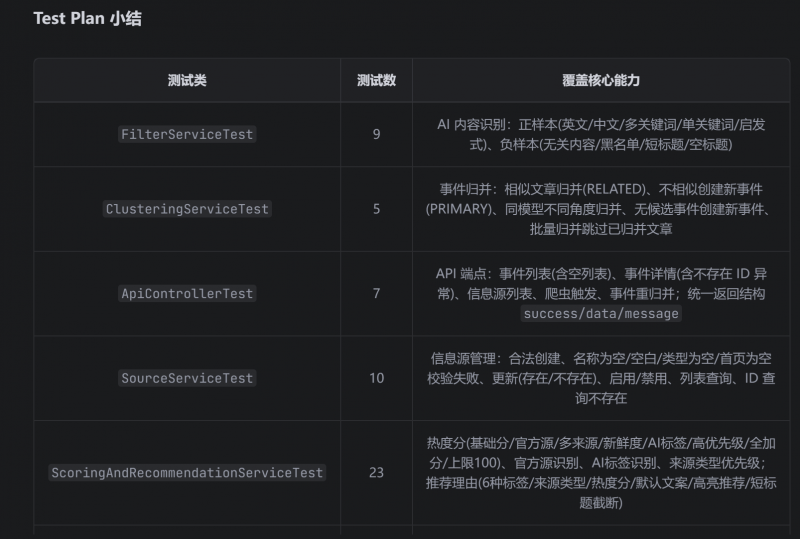
測試中有一個失敗。Agent識别後也是快速得到了修複。

但是GLM5.2有一個很明顯的問題,就是不穩定,不穩定是因為使用的人太多了有時候要排隊,其次就是價格問題。
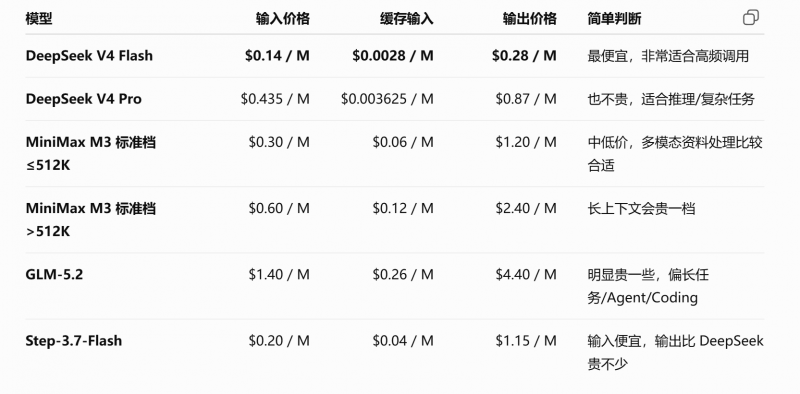
這個任務消耗了9.8.但實際消耗了12塊左右。
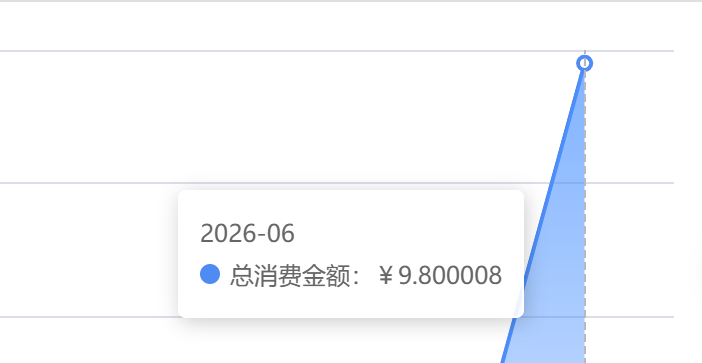
我也打算嘗試使用聚合平台來測試,在聚合平台上面使用gemini-3.5-flash,來進行測試。但測試到一半就不行了,因為太貴。我以為十元可以跑完這個測試,但是跑一半就提示餘額不足了。
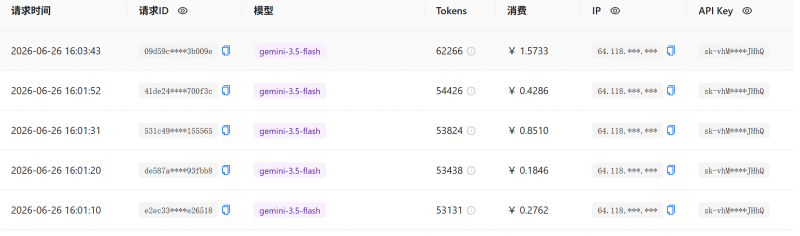
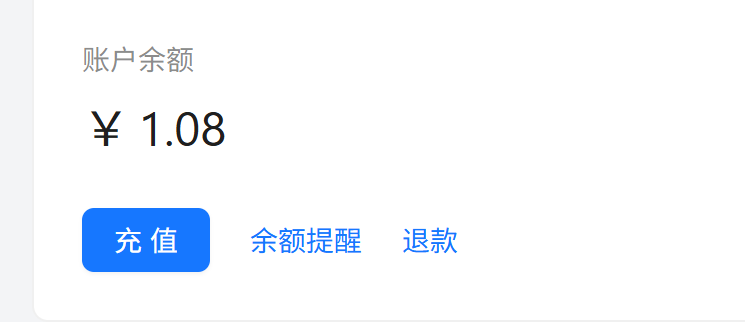
而且利用聚合平台還有一個問題就是不穩定。

最後
所以這篇測下來,我對 Step-3.7-Flash 的定位會更清楚一點。
它不是去和 Pro 檔硬拼極限推理,也不是去和效率檔拼最低單價。它更像是卡在中間那個最實用的位置:速度夠快、成本能控、穩定性也能支撐連續任務。
尤其是生産級 Agent 場景裡,這個優勢會更明顯。比如高頻調用、多輪執行、低延遲響應、代碼測試、數據處理、辦公自動化,再加上一些多模态輸入,這類任務并不一定需要最強模型,但一定需要模型跑得快、跑得穩、跑得便宜。
從這個角度看,Step-3.7-Flash 更像是“效率前沿”賽道裡的綜合最優解。
如果你的任務是複雜長鍊推理、深度研究、架構級代碼設計,那還是優先選 Pro 檔。但如果是日常生産環境裡的高頻 Agent 工作流,我會更傾向于先把 Step-3.7-Flash 放進候選名單裡。